Perjalanan Eksperimen Local LLM
LLM
Sebelum lebih lanjut cerita tentang eksperimen ini, apa sih LLM itu?
LLM atau Large Languange Model, simpelnya merupakan salah satu model dari kecerdasan buatan (Artificial Intelligence), yang mempunyai banyak parameter di dalamnya. Parameter disini simpelnya pengetahuan yang dimiliki sebuah model, bisa miliaran dan bahkan triliunan.
Untuk informasi lebih lengkap bisa baca salah satu referensi buku disini https://books.google.co.id/books?id=jvpaEQAAQBAJ&lpg=PR3&ots=qQhkQTwZon&lr&hl=id&pg=PA32#v=onepage&q&f=false
Mungkin biar gampang, model-model ini yang sering kita gunakan ada ChatGPT, Gemini, Claude dan lain-lain. Mereka punya parameter yang sangat sangat besar, bisa ratusan B (Billion). Contoh model open source dari OpenAI ada gpt-oss yang punya 120B, atau yang baru baru ini rilis dari Gemini, yaitu Gemma4 yang punya 31B parameter tapi kemampuannya lebih dari gpt-oss dengan parameter yang jauh lebih besar.
 https://huggingface.co/openai/gpt-oss-120b
https://huggingface.co/openai/gpt-oss-120b
 https://huggingface.co/google/gemma-4-31B-it
https://huggingface.co/google/gemma-4-31B-it
Kenapa penasaran?
Saya sering denger tentang tools Ollama, Qwen, Deepseek atau model model lain, tapi ga pernah bener bener tau mereka itu apa sih? model itu apa dan satuan B itu apa?
Dari sini saya jadi penasaran dan coba cari tau satu persatu. Ternyata Ollama merupakan salah satu platform yang memungkinkan kita buat ngejalanin model open source di laptop kita. Tapi kalo kita cari lebih dalam lagi, ollama ini bisa kita gunakan sebagai sebuah library untuk nantinya gunain AI di aplikasi kita.
Dari sini jadi menarik, sebelum saya bisa fungsiin AI di aplikasi saya nantinya dengan metode RAG, saya mesti ngerti dulu cara running AI di local, cari tau tentang Context, Parameter, Top P, Top K dan banyak istilah lainnya.
Spesifikasi
Saya jalanin LLM di local ini dengan laptop Advan Workplus CPU Ryzen 5 6600H, GPU nya integrated Radeon 680M max VRAM 2GB dengan RAM 16GB. OS yang saya gunakan CachyOS dengan base Arch.
Tools
Setelah cari tau tentang tools buat jalanin LLM di local, saya ketemu dengan tools yaitu Ollama. Cara install nya gampang, senormalnya install aplikasi di masing masing OS. Ada juga alternatif lain yaitu LLM Studio, tapi saya belum pernah coba.
Untuk eksperimen chatting, saya pernah coba beberapa tools seperti Open WebUI dan beberapa TUI, saya ga pernah nemu yang ringan kurang dari 1GB untuk runningnya. Asumsi saya sih karena semua tools itu jalanin pake Python jadi cukup berat. Jadi saya vibe coding alternatif untuk sekedar chat biasa dan saya gunakan untuk eksperimen yaitu https://fadhil-sabar.github.io/ollama-interaction/.
Memori
Dari penjelasan sebelumnya, LLM itu punya parameternya masing masing, semakin besar parameter yang dimiliki semakin besar juga ukurannya, dan semakin besar model itu akan consume memory kita. Buat ngejalanin nya Ollama secara otomatis ngasih kita opsi, bisa dari GPU (VRAM) atau CPU (RAM).
Jadi saya mesti cari tau dulu model apa yang kemungkinan akan fit di laptop saya. Pertama kali yang saya coba adalah Qwen2.5-Coder 7B, seperti namanya model ini punya 7B parameter dan ukuran modelnya 4.7GB, artinya masih bisa fit di RAM saya.
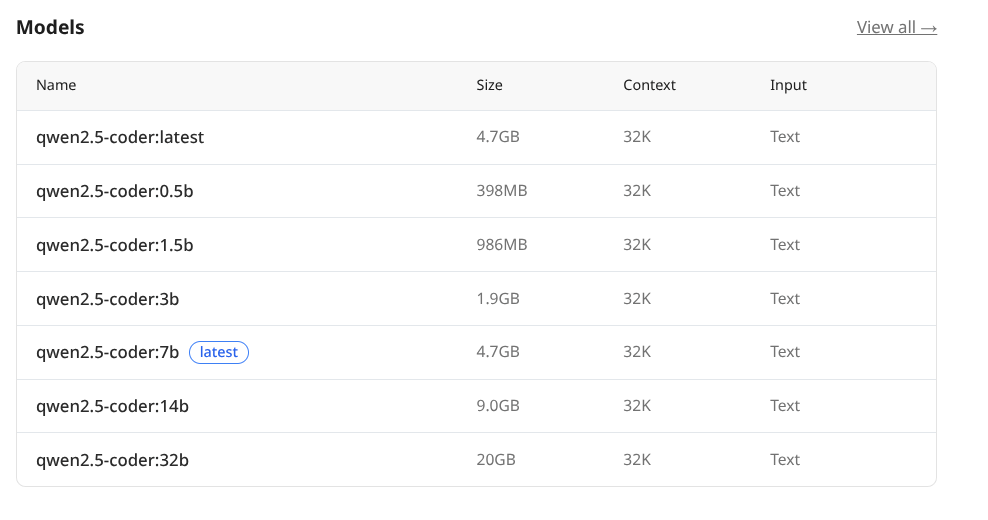 https://ollama.com/library/qwen2.5-coder
https://ollama.com/library/qwen2.5-coder
 https://deepwiki.com/ollama/ollama/1.2-system-requirements
https://deepwiki.com/ollama/ollama/1.2-system-requirements
Eksperimen
Setelah saya run, ternyata saya hanya mendapat kurang dari 10 tops di mode CPU, dan ini berat banget bahkan cuma dapet kurang dari 5 tops kalo dengan GPU.
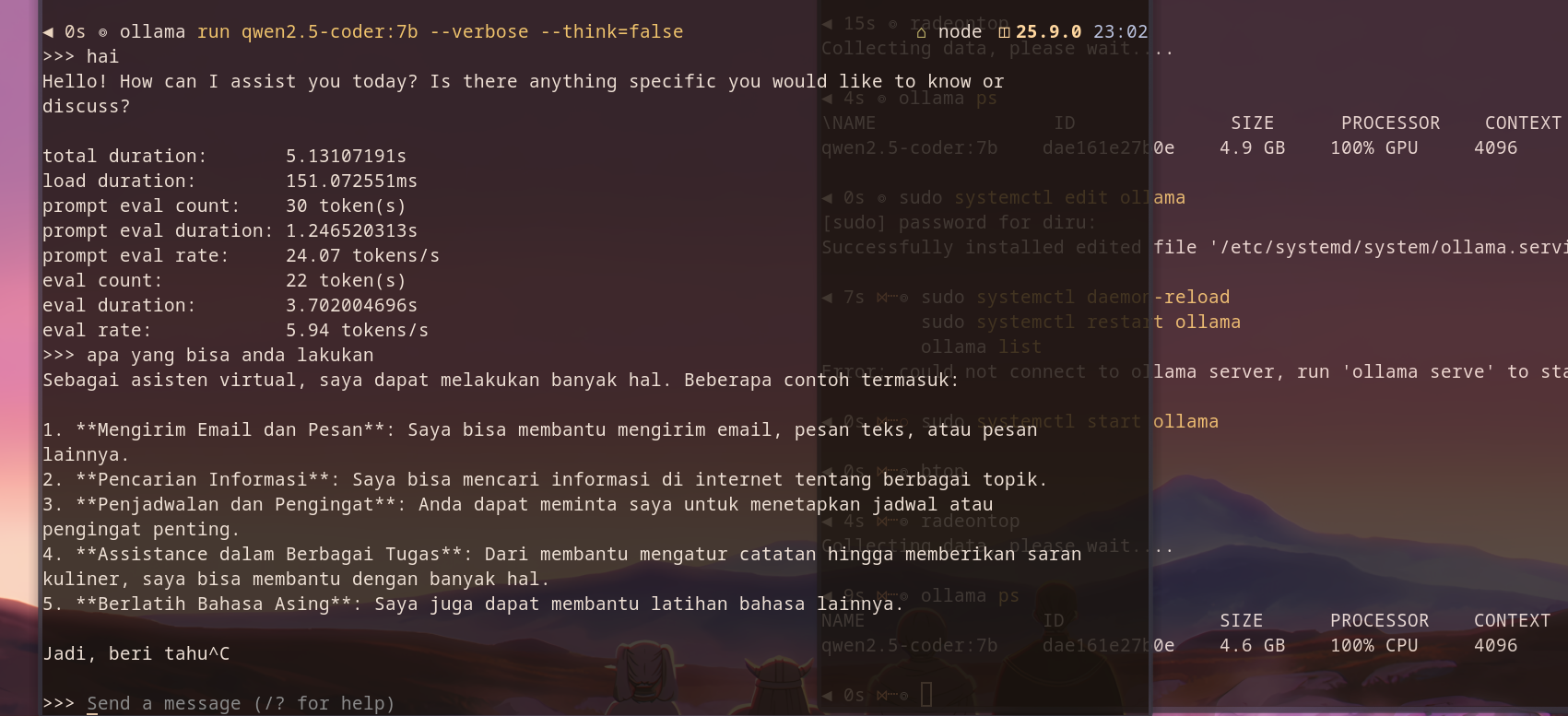 qwen2.5-coder:7b CPU
qwen2.5-coder:7b CPU
Tops disini berarti Token per second, artinya jumlah token yang dihasilkan oleh model, semakin besar maka semakin cepat. Referensi lengkap bisa dibaca disini https://grokipedia.com/page/Tokens_per_second.
Akhirnya saya coba eksperimen lagi dengan model lain yaitu llama3.2:3b. Hasilnya adalah 13.37 tokens/s untuk GPU dan mode CPU mendapat angka yang serupa. Menurut saya 13 tops masih tetap kencang untuk di local, tapi masih belum cukup cepat di mata saya yang terbiasa liat di model SAAS seperti Gemini, walau memang ga apple to apple speknya.
Alhasil saya coba terus model yang lain, mulai dari qwen2.5-coder:3b, qwen2.5:1.5b, versi instruct qwen2.5-coder:7b-instruct-q4_K_M, qwen2.5-coder:1.5b hingga ke model qwen3.5:0.8b yang baru rilis pada waktu itu. Akhirnya menemukan sweet spot di qwen2.5-coder:1.5b, karena dari kecepatan dapat di atas 20 tokens/s dan kemampuan untuk tanya seputar coding masih cukup mumpuni.
Istilah instruct / quantization disini berarti teknik untuk mengurangi memori yang diperlukan untuk menjalankan LLM tapi tetap mempertahankan akurasi jawaban, referensi lengkap bisa dilihat disini https://medium.com/@abhinaykrishna/llm-quantization-in-depth-1fa65ac24f2a.
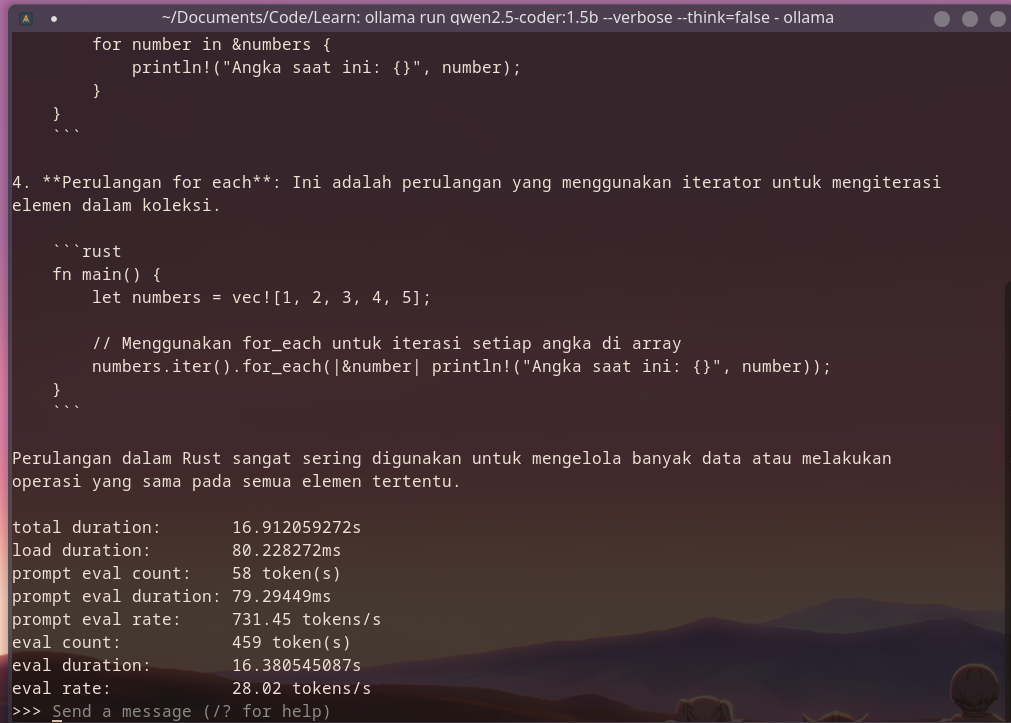 qwen2.5-coder:1.5b CPU
qwen2.5-coder:1.5b CPU
llama.cpp dan lmstudio
Eksperimen saya berlanjut melalui beberapa tools lain, yaitu ada llama.cpp dan lmstudio. Tools pertama yang saya coba dan langsung amaze adalah llama.cpp.
Dari segi speed, saya rasa cukup jauh perbedaan token per secondnya. Tapi mungkin ada beberapa faktor dari quantization yang saya gunakan.
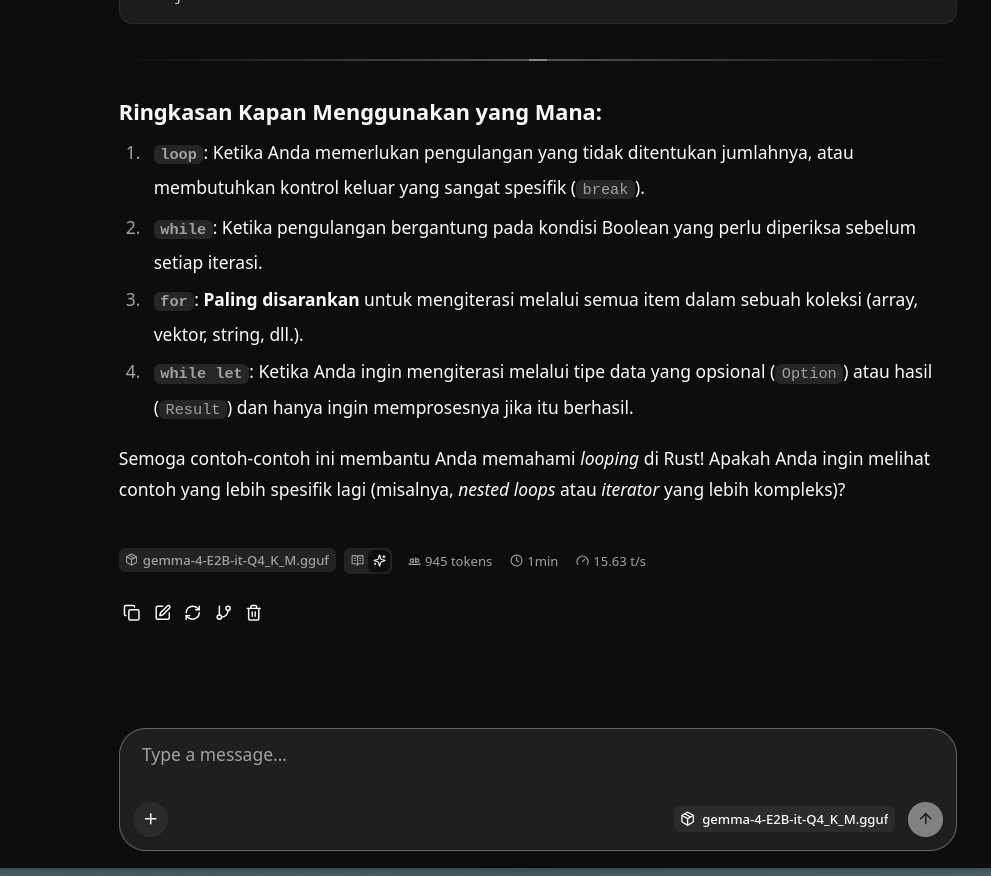 gemma4:e2b Q4_K_M CPU
gemma4:e2b Q4_K_M CPU
Ini sebagai contoh ketika saya run gemma4 e2b bisa dapat sekitar 15 token/s, dan ini lumayan banget buat model berukuran 2,9GB. Satu poin kelebihan juga, llama.cpp punya UI bawaan buat kita langsung interaksi sama modelnya, dan sangat customizable untuk parameternya.
Terakhir saya coba buat pake lmstudio, karena ternyata llama.cpp digunakan sebagai backend nya. Versi lmstudio yang saya gunakan disini yaitu mode headless, jadi tanpa UI dan buat ngejalanin endpoint aja.
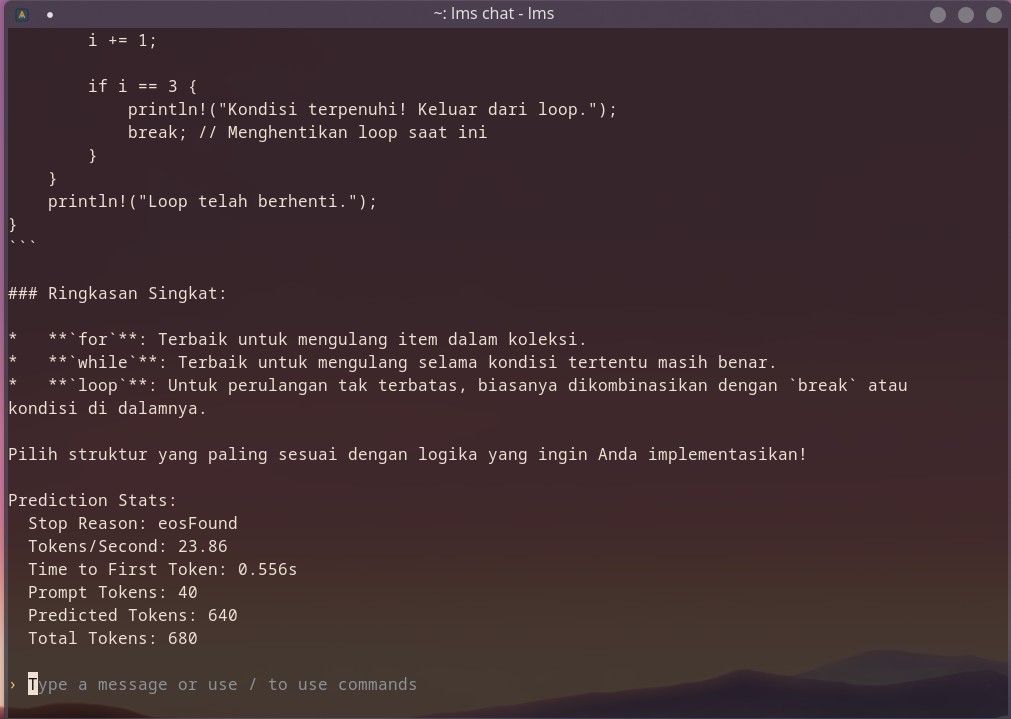 gemma4:e2b Q4_K_M lmstudio
gemma4:e2b Q4_K_M lmstudio
Saya ngeliat suatu hal yang unik disini, lmstudio secara effortless akan coba running dengan GPU terlebih dahulu. Kalau dirasa kurang maka akan digabung dengan CPU, menggunakan memory RAM. Hal ini berbeda dengan llama.cpp atau ollama yang mengharuskan kita menginstal dengan versi ROCM atau CUDA.
Kesimpulan
Tools yang saya sarankan untuk coba running local model adalah lmstudio. Karena dari segi interface dia paling mudah untuk digunakan, dan dari segi performa lebih baik dari ollama. Model yang kita bisa gunakan juga tidak terbatas, kita bisa download dari huggingface atau dari interface lmstudio nya langsung.
Tapi kalau penasaran buat coba ubah parameter lebih detail, dan mau cari tau performa yang lebih raw maka lebih baik coba llama.cpp. Ollama cukup bagus buat starter, tapi performanya paling rendah menurut saya.
Kalau untuk sekarang saya menggunakan Claude Code, mix dengan Gemini CLI dan OpenCode. Saya cukup amaze dengan kemampuan model frontier nya.
Dari percobaan ini saya jadi tau gimana llm bekerja, paremeter yang ada di setiap model, kenapa setiap model bisa punya speed dan jawaban yang berbeda beda. Mungkin kedepannya akan coba buat pelajarin RAG dan bikin chatbot sederhana.
Terima kasih karena sudah baca dan let’s discuss tentang llm ini!